|
Создание большинства бизнес-приложений требует решения целого комплекса задач по хранению данных, обеспечению параллельного доступа к ним, их целостности и защиты. Для этой цели обычно используются готовые системы управления базами данных (СУБД).
Конечно, любая СУБД требует адаптации к условиям конкретного предприятия, которую организации часто разбивают на две задачи: проектирование данных поручается специалистам по базам данных, а программная поддержка выполнения транзакций - программистам. Реализация такого подхода, имеющего, конечно, свои преимущества, сопряжена с решением ряда серьезных проблем. Надо откровенно признать, что в деятельности разработчиков баз данных и программистов существуют серьезные различия, которые определяются различиями в технологии и в навыках разработки. Проектировщики баз данных обычно описывают проблемную область в терминах "долгоживущих" монолитных таблиц с информацией, в то время как программисты привыкли воспринимать мир в терминах потоков управления.
Если эти два подхода не удастся совместить в рамках одного проекта, то добиться целостности проектного решения для более или менее сложной системы будет практически невозможно. Для системы, в которой главное -данные, мы должны добиться равновесия между базой данных и приложением. База данных, разработанная без учета того, как она в дальнейшем будет использоваться, оказывается, как правило, неуклюжей и неэффективной. В свою очередь изолированное приложение может предъявить невыполнимые требования к базе данных, что приведет к серьезным проблемам с обеспечением целостности информации.
Еще в недалеком прошлом бизнес-приложения выполнялись на больших ЭВМ, что воздвигало для обычного служащего почти непреодолимые барьеры на пути к нужной ему информации. Однако с пришествием персонального компьютера ситуация резко переменилась: доступные инструменты обработки и хранения данных вкупе с компьютерными сетями позволили соединить компьютеры не только внутри офиса, но и между предприятиями, отделенными друг от друга тысячами километров. Одним из основных факторов, способствовавших такому изменению, было внедрение архитектуры клиент-сервер. Как отмечает Мимно, "Резкий переход к архитектурам клиент-сервер на базе персональных компьютеров был вызван прежде всего требованиями бизнеса. Перед лицом возросшей конкуренции и ускорившегося цикла выпуска новой продукции, возникла потребность в более быстром продвижении товаров на рынок, увеличении объема услуг, предоставляемых клиентам, более оперативном отслеживании тенденций развития рынка, общем уменьшении расходов" [1]. В этой главе мы рассмотрим пример информационно-управляющей системы (MIS, management information system) и покажем, как объектно-ориентированная технология предлагает единую концепцию организации базы данных и разработки соответствующего приложения для архитектуры клиент-сервер.
10.1. Анализ
Определение границ задачи
Требования к системе складского учета показаны на врезке. Это достаточно сложная программная система, затрагивающая все аспекты, связанные с движением товара на склад и со склада. Для хранения продукции служит, естественно, реальный склад, однако именно программа является его душой, без которой он потеряет свою функцию эффективного центра распределения.
При разработке такой системы заказчикам необходимо частично переосмыслить весь бизнес-процесс и учесть уже имеющиеся программы, чтобы не потерять вложенные средства (см. главу 7). И хотя некоторое улучшение производительности ведения дел в компании может быть достигнуто просто за счет автоматизации уже существующей системы учета товаров "вручную", радикального улучшения можно добиться только при кардинальном пересмотре ведения бизнеса. Вопросы реинжениринга связаны с системным планированием и выходят за рамки нашей книги. Однако, так же как архитектура системы определяет ее реализацию, общее видение бизнеса определяет всю систему. Исходя из данной предпосылки, начинать следует с рассмотрения общего плана ведения складского учета. По результатам системного анализа можно выделить семь основных функций системы:
| ® Учет заказов |
Прием заказов от клиентов и ответы на запросы клиентов о состоянии заказов. |
| ® Ведение счетов |
Направление счетов клиентам и отслеживание платежей. Прием счетов от поставщиков и отслеживание платежей поставщикам. |
| ® Отгрузка со склада |
Составление спецификаций на комплектацию товаров, отправляемых со склада клиентам. |
| ® Складской учет |
Постановка прибывающих товаров на учет и снятие товаров с учета при отправке заказов. |
| ® Закупки |
Заказ товаров поставщикам и отслеживание поставок. |
| ® Получение |
Принятие на склад товаров от поставщиков. |
| ® Планирование |
Выпуск отчетов, в том числе отражающих тенденции спроса на отдельные виды товаров и активность поставщиков. |
| Требования к системе складского учета
В качестве части стратегии по проникновению компании, занимающейся торговлей по каталогам, на новые участки рынка, было решено создать ряд относительно автономных региональных складов продукции. Каждый такой склад несет ответственность за учет товаров и выполнение заказов. В целях повышения эффективности своей работы склад обязан сам поддерживать ту номенклатуру товаров, которая в наилучшей степени соответствует потребностям местного рынка. Номенклатура, таким образом, может быть разной для каждого региона. Кроме того, номенклатура должна оперативно меняться в соответствии с изменяющимися потребностями клиентов. Головная компания хотела бы иметь на всех складах одинаковые системы учета.
Основными функциями системы являются:
-
Учет товаров, приходящих от разных поставщиков, при их приеме
на склад.
-
Учет заказов по мере их поступления из центральной удаленной
организации; заказы также могут приниматься по почте. Их обработка ведется
на местах.
-
Генерация указаний персоналу, в частности, об упаковке товаров.
-
Генерация счетов и отслеживание оплат.
-
Генерация запросов о поставке и отслеживание платежей поставщикам.
Кроме автоматизации стандартных складских операций, система
также должна предоставлять богатые возможности по генерации различных форм
отчетности, в том числе отражающих тенденции развития рынка, списков наиболее
надежных и ненадежных поставщиков и клиентов, материалов для рекламных
компаний. |
Не удивительно, что системная архитектура будет отражать
перечисленные функциональные свойства. На рис.10-1 приведена диаграмма,
иллюстрирующая состав вычислительных элементов сети. Эта структура является
типичной для большинства информационных управляющих систем: группы персональных
компьютеров передают информацию на центральный сервер баз данных, который
служит центральным хранилищем всех существенных для предприятия данных.
Рассмотрим некоторые детали структуры сети. Во-первых,
хотя на рисунке мы видим, что каждый компьютер принадлежит только одной
функциональной группе, это не означает, что на нем нельзя выполнять другие
операции: отдел бухгалтерского учета должен, например, иметь возможность
осуществлять общие запросы к базе данных, а отдел закупок, в свою очередь,
просматривать бухгалтерскую информацию, касающуюся платежей поставщикам.
Кроме того, руководство компании может в соответствии со своими соображениями
перераспределять компьютерные ресурсы между отделами фирмы. Требования
по защите информации накладывают, однако, некоторые ограничения на доступ
к ней: кладовщик, например, не должен иметь возможность отсылать платежные
документы. Контроль за доступом к данным обычно осуществляется с помощью
общих для всей системы механизмов защиты данных.
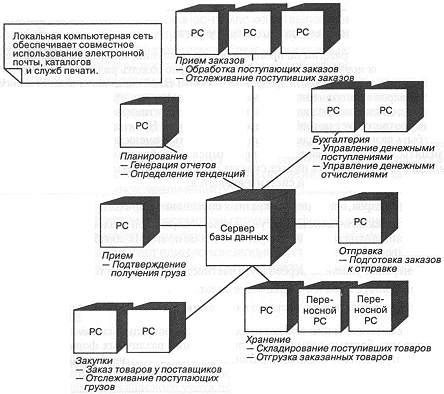 Рис. 10-1. Сеть системы складского учета.
Рис. 10-1. Сеть системы складского учета.
Мы предполагаем существование компьютерной сети (LAN), связывающей все компьютеры и обеспечивающей работу общих механизмов взаимодействия пользователей: электронной почты, разделенного доступа к каталогам, вывода информации на сетевой принтер, коммуникаций. Для нашей системы складского учета выбор сетевой операционной среды не так уж и важен, лишь бы она надежно и эффективно обеспечивала взаимодействие пользователей.
Присутствие в нашей схеме переносных персональных компьютеров отражает возможности передовых коммуникационных технологий беспроводной связи. Такой техникой планируется оснастить кладовщиков. По мере поступления новых товаров на склад они будут оперативно заносить в компьютер информацию о его количестве и местоположении на складе, и передавать ее непосредственно на сервер. При необходимости отгрузки товара со склада информация о его количестве и расположении будет сообщаться кладовщику, который передаст ее грузчикам.
Упомянутые технологические средства не сравнимы с космическими станциями, - вся аппаратная часть является стандартной. Что касается программной части, то мы надеемся, что значительная ее часть также будет составлена из стандартных компонентов. Для решения многих локальных подзадач выгодно приобрести готовые электронные таблицы, бухгалтерские пакеты и средства групповой работы. Однако основной движущей силой системы должна стать программа складского учета, связывающая в единое целое все ее составные части.
В подобных приложениях собственно вычисления занимают очень мало места. Основная задача состоит в обеспечении хранения, доступа и пересылки больших объемов данных. Таким образом, большинство архитектурных решений будет нацелено на работу с декларативной информацией (какие товары присутствуют на складе, что скрывается под их обозначением, где они расположены), а не с процедурными вопросами (каким образом идет перемещение товара). Разработка проекта будет основываться на основном принципе объектно-ориентированного подхода: выявление ключевых абстракций, формирующих словарь предметной области, и механизмов, оперирующих данными абстракциями.
Бизнес-процесс ставит перед нашей системой важное условие: она должна быть открытой для дальнейших модификаций. В ходе анализа нам необходимо выделить ключевые абстракции, играющие в данный момент важную роль в деятельности фирмы: определить типы хранимых в базе данных; перечислить отчеты, которые должны генерироваться; научиться обрабатывать запросы и проводить все остальные транзакции, необходимые в деятельности компании. Именно в данный момент, так как бизнес подвержен постоянным изменениям, фирма все время ищет новые области вложения капитала, и информационная система должна легко перестраиваться в соответствии с модернизацией стратегии фирмы и/или с ее выходом на новые рынки. Устаревшая программная система может стать причиной неудач в бизнесе и вызвать непроизводительную трату людских ресурсов. Таким образом, при проектировании системы складского учета необходимо предусмотреть возможность внесения в нее последующих изменений. Опыт показывает, что наиболее подвержены изменениям следующие элементы программы:
-
виды хранимых данных;
-
аппаратная часть системы.
Каждый из складов с течением времени меняет ассортимент хранимых товаров, начинает работать с новыми клиентами и поставщиками, иногда теряя при этом старых. Может неожиданно оказаться, что о клиентах необходимо хранить дополнительную, не предусмотренную системой информацию [Рассмотрим, например, последствия внедрения новых технологий, которые предоставляют услуги интерактивного телевидения каждой домохозяйке. Можно предположить, что в будущем покупатели смогут делать заказы в электронном виде и оплачивать их также по сети. Так как стандарты в этих областях меняются почти ежедневно, в зависимости от того, какие компании занимают ведущие позиции, разработчику приложений для конечного пользователя невозможно точно предугадать протокол взаимодействия с такой системой. Лучшее, что мы можем предпринять как архитекторы системы, - это сделать осмысленные предположения и инкапсулировать их в нашей системе, чтобы можно было приспособиться, когда уляжется пыль битвы за доминирование на дорогах информации - битвы, в которой разработчик отдельного приложения значит не больше, чем пешка. Это обстоятельство приводит нас к главному доводу в пользу объектно-ориентированной технологии: как мы уже убедились, объектно-ориентированный подход позволяет создавать гибко приспосабливающиеся архитектуры, что очень существенно для выживания на рынке]. Кроме того, аппаратные технологии все еще развиваются быстрее программных, и компьютеры за несколько лет морально устаревают. Никто, однако, не в состоянии часто менять большие и сложные программные комплексы, это не рационально и непозволительно потому, что время и затраты на создание новой системы часто превосходят время и затраты на покупку и установку новых компьютеров. Внедряя новую систему только по той причине, что старая выглядит устаревшей, вы рискуете своим бизнесом: стабильность и надежность работы являются необходимым свойством программного обеспечения, которое должно обслуживать повседневную деятельность фирмы.
Один из выводов, таким образом, заключается в том, что с течением времени можно ожидать смены интерфейса пользователя. В прошлом бизнес-приложения имели обычный текстовый интерфейс, и это считалось нормальным. Однако общее снижение цен на компьютеры и широкое распространение графических интерфейсов пользователя обуславливают необходимость внедрения графических приложений. Надо помнить, что для системы складского учета интерфейс пользователя является всего лишь небольшой (хотя и важной) частью. Ядром системы является база данных; пользовательский интерфейс можно рассматривать как оболочку вокруг этого ядра. Для данной системы можно (и даже желательно) создать несколько интерфейсов. Простой, базирующийся на меню, - для клиентов, заполняющих заявки на товар. Современный, типа Windows, - для решения бухгалтерских задач, а также планирования и закупок. Отчеты могут печататься в пакетном режиме, однако некоторым менеджерам могут понадобиться средства для просмотра графиков на экране. Кладовщику нужен простой интерфейс: окна и мышь не подходят для работы в заводских условиях. Мы не будем подробно останавливаться на вопросах, связанных с интерфейсом пользователя; в системе складского учета может быть реализован практически любой из существующих интерфейсов, и это не скажется на ее архитектуре.
Перед дальнейшим обсуждением задачи отметим две важные вещи. Во-первых, при разработке будет использоваться стандартная реляционная база данных (СУРБД), вокруг которой строится программное приложение. Заниматься созданием своей СУБД в данной ситуации просто бессмысленно; нам придется реализовать большинство основных свойств стандартной базы данных, что резко увеличит расходы, а полученный в результате продукт окажется функционально куда менее гибким. Преимущество стандартной реляционной СУБД заключается также в ее относительной переносимости. Большинство распространенных баз данных адаптировано к различным платформам, от персональных компьютеров до мэйнфреймов. Во-вторых, как видно из рис. 10-1, мы хотим, чтобы система складского учета функционировала в распределенной компьютерной сети. Мы планируем разместить всю базу данных на одном компьютере, к которому будут иметь доступ все компьютеры сети. Такая схема и реализует архитектуру клиент-сервер; компьютер, на котором установлена база, является сервером. К нему подключаются несколько клиентов. Конкретный компьютер, на котором работает пользователь, не имеет для сервера никакого значения. Таким образом, наше приложение должно работать на любом компьютере сети, и внедрение новых аппаратных технологий будет оказывать минимальное влияние на функционирование системы.
Архитектура клиент-сервер
Хотя данный раздел и не является подробным обзором архитектуры клиент-сервер, некоторые замечания по этой теме необходимо сделать, так как они напрямую относятся к выбору архитектурных решений для нашей системы.
Что можно отнести к категории клиент-сервер, а что нет, до сих пор является предметом жарких дискуссий [Также как и вопрос о том, что можно считать объектно-ориентированным, а что - нет]. В нашем случае будет достаточно определения решений на базе клиент-сервер как "децентрализованной архитектуры, позволяющей конечным пользователям получать гарантированный доступ к информации в разнородной аппаратной и программной среде. Приложения клиент-сервер сочетают пользовательский графический интерфейс клиента с реляционной базой данных, расположенной на сервере" [2]. Структура таких приложений подразумевает возможность совместной работы пользователей; при этом ответственность за выполнение тех или иных функций ложится на различные, независимые друг от друга элементы открытой распределенной среды. Берсон далее утверждает, что приложение клиент-сервер обычно можно разделить на четыре компонента:
| ® Логика представления |
Часть приложения, обеспечивающая связь с инструментами конечного пользователя. Таким инструментом может быть терминал, считыватель штрих-кодов или переносной компьютер. Включает функции: формирование изображения, ввод и вывод информации, управление окнами, поддержка клавиатуры и мыши. |
| ® Бизнес-логика |
Часть приложения, использующая информацию, вводимую пользователем, и информацию, содержащуюся в базе данных, для выполнения транзакций, удовлетворяющих бизнес-правилам. |
| ® Логика базы данных |
Часть приложения, "манипулирующая данными приложения". В реляционной базе данных подобные действия обеспечиваются с помощью языка SQL" (SQL, Structured Query Language, язык структурированных запросов). |
| ® Механизмы обращения |
"Непосредственная работа с базой данных, к базе данных выполняемая СУБД... В идеальном случае механизмы СУБД прозрачны для бизнес-логики приложения" [3]. |
Один из основных вопросов при проектировании архитектуры системы состоит в оптимальном распределении узлов обработки в сети. Принятие решений здесь усложняется тем, что инструменты и стандарты для архитектур клиент-сервер обновляются с ошеломляющей быстротой. Архитектор должен разобраться, например, с POSIX (Portable Operating System Interface, интерфейс переносимых операционных систем), OSI (Open Systems Interconnection, связь открытых систем), CORBA (Common Object Request Broker, единый брокер объектных запросов), объектно-ориентированным расширением языка SQL (SQL3), и рядом специальных решений фирм-поставщиков типа OLE (Object Linking and Embedding, связывание и внедрение объектов) фирмы Microsoft [Именно по этой причине хорошие архитекторы информационных систем получают либо громадные деньги за свое мастерство, либо - массу удовольствия от самого процесса сборки многих разрозненных технологий в одно согласованное целое].
Но на архитектурные решения оказывает влияние не только обилие стандартов. Имеют значение и такие вопросы, как защита данных, производительность системы и ее объем. Берсон предлагает архитектору несколько основных правил проектирования приложении клиент-сервер:
-
Компонент логики представления обычно устанавливается там же, где и терминал ввода-вывода, то есть на компьютере конечного пользователя.
-
Учитывая возросшую мощность рабочих станций, а также тот факт, что логика представления установлена на машине клиента, имеет смысл там же разместить и некоторую часть бизнес-логики.
-
Если механизмы обращения к базе данных связаны с бизнес-логикой, и если клиенты поддерживают некоторое взаимодействие низкого уровня и квазистатические данные, то механизмы обращения к базе данных можно также разместить на стороне клиента.
-
Принимая во внимание тот факт, что сетевые пользователи обычно организованы в рабочие группы, и что рабочая группа совместно использует базу данных, фрагменты бизнес-логики и механизмов обращения к базе данных, которые являются общими, и сама СУБД должны находиться на сервере [4].
Если нам удастся выбрать верные архитектурные решения и успешно реализовать их тактические детали, модель клиент-сервер даст системе целый ряд преимуществ. Берсон особо выделяет, что архитектура клиент-сервер:
-
Позволяет более эффективно использовать новые компьютерные технологии автоматизации.
-
Позволяет перенести обработку данных ближе к клиенту, что снижает загрузку сети и уменьшает продолжительность транзакций.
-
Облегчает использование графических интерфейсов пользователя, которые стали доступны на мощных современных рабочих станциях.
-
Облегчает переход к открытым системам [5]. Надо выделить, однако, следующие моменты риска:
-
Если значительная часть логики приложения окажется вынесенной на сервер, то последний может стать узким местом системы, замедляющим работу пользователей (как это часто бывало при использовании мэйнфреймов в архитектуре хозяин-раб).
-
Распределенные приложения... сложнее нераспределенных [6].
Мы уменьшим этот риск, используя объектно-ориентированный подход к разработке.
Сценарии работы
Сейчас, когда мы представили себе систему в целом, продолжим наш анализ и изучим несколько сценариев ее работы. Сначала перечислим ряд основных режимов использования:
-
Клиент звонит по телефону в удаленную телемаркетинговую организацию, чтобы сделать заказ.
-
Клиент посылает заказ по почте.
-
Клиент звонит, чтобы узнать состояние дел по его заказу.
-
Клиент звонит, чтобы добавить или убрать некоторые позиции из заказа.
-
Кладовщик получает указание отгрузить клиенту необходимое количество товара.
-
Служба доставки получает со склада заказанные клиентом товары и готовит их к отправке.
-
Бухгалтерия готовит счет для клиента.
-
Отдел закупок готовит заказ на новый товар.
-
Отдел закупок добавляет или удаляет имя поставщика из списка.
-
Отдел закупок запрашивает поставщика о состоянии заказа.
-
Отдел приема товара принимает груз от поставщика и проверяет его соответствие заказу.
-
Кладовщик заносит новый товар в список.
-
Бухгалтерия отмечает прибытие нового товара.
-
Плановый отдел генерирует отчет о показателях продаж по различным типам продуктов.
-
Плановый отдел генерирует отчет для налоговых органов с указанием количества товаров на складах.
Каждый из основных сценариев может включать в себя ряд вторичных:
-
Заказанного клиентом товара нет на складе.
-
Заказ клиента неверно оформлен, или в нем присутствуют несуществующие или устаревшие идентификаторы товаров.
-
Клиент звонит, чтобы проверить состояние заказа, но не помнит точно что, кем и когда было заказано.
-
Кладовщик получил расходную накладную, но некоторые перечисленные в ней товары не нашлись.
-
Служба доставки получает заказанные клиентом товары, но они не соответствуют заказу.
-
Клиент не заплатил по счету.
-
Отдел закупок делает новый заказ, но поставщик либо ушел из бизнеса, либо больше не поставляет заказанный тип товара.
-
Отдел приема товара принимает груз, не полностью соответствующий заказу.
-
Кладовщик хочет разместить на складе новый товар, но обнаруживается,
что для него нет места.
-
Изменяются налоговые коды, что вынуждает плановый отдел составить новый инвентаризационный список находящихся на складе товаров.
Для системы такой сложности, наверно, будут выявлены десятки основных сценариев и еще большее количество вторичных. Этот этап анализа может занять несколько недель, пока не удастся добиться более или менее подробного уровня детализации [Но помните о параличе анализа: если фаза анализа не укладывается в сроки, диктуемые бизнесом, то "оставь надежду всяк сюда входящий", - этот бизнес не для вас]. Поэтому мы настоятельно советуем применять правило восьмидесяти процентов: не ждите, пока сформируется полный список всех сценариев (никакого времени на это не хватит), изучите около 80% наиболее интересных из них и, если возможно, попытайтесь хотя бы оценочно проверить правильность общей концепции. В этой главе мы подробно остановимся на двух основных сценариях.
На рис. 10-2 представлен сценарий, в котором покупатель размещает свой заказ в телемаркетинговой фирме. В выполнении этой системной функции задействовано несколько различных объектов. И хотя управление осуществляется взаимодействием клиента (aCustomer) с агентом (anAgent), есть и другие ключевые объекты, а именно: сведения о клиенте (aCustomerRecord), база данных о товарах (inventoryDatabase) и заявка на комплектование (aPackingOrder), являющиеся абстракциями системы складского учета. Этот список абстракций формируется как раз на этапе рассмотрения сценариев работы.
 Рис. 10-2. Сценарий заказа.
Рис. 10-2. Сценарий заказа.
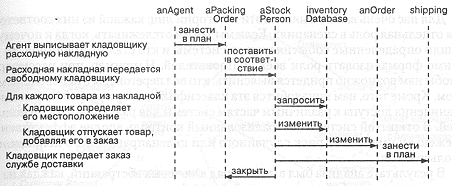 Рис. 10-3. Сценарий выполнения заказа.
Рис. 10-3. Сценарий выполнения заказа.
Рис. 10-3 отражает продолжение данного сценария. На нем представлена схема взаимодействия кладовщика и расходной накладной. Мы видим, что здесь кладовщик является главной фигурой. Он взаимодействует с другими объектами, например с отгрузкой (shipping), которой не было в предыдущем сценарии. Однако большинство объектов, фигурирующих на рис. 10-3, присутствуют также и на рис. 10-2, хотя они играют в этих сценариях различные роли. Например, в сценарии взаимодействия с клиентом мы создаем заказ (anOrder) как документ, в котором отражены требования клиента. В складском сценарии тот же самый заказ исполняется.
При составлении каждого из таких сценариев мы должны постоянно задавать себе ряд вопросов. Какой объект будет нести ответственность за выполнение того или иного действия? Как объект будет проводить ту или иную операцию: самостоятельно или используя свойства другого объекта? Не слишком ли много операций вменяется в круг обязанностей данного объекта? Что произойдет при ошибке в ходе выполнения сценария (какие постусловия могут нарушиться)? Что случится, если будут нарушены некоторые предусловия?
Занимаясь подобным антропоморфизмом для каждого функционального свойства системы, мы откроем в системе целый ряд интересных объектов высокого уровня. Сначала перечислим лиц, взаимодействующих с системой:
-
Customer - клиент
-
Supplier - поставщик
-
OrderAgent - сотрудник отдела продаж
-
Accountant - бухгалтер
-
ShippingAgent - сотрудник отдела отгрузки
-
Stockperson - кладовщик
-
PurchasingAgent - сотрудник отдела закупок
-
ReceivingAgent - сотрудник отдела приема товаров
-
Planner - сотрудник планового отдела
Для нас очень важно выявить эти категории лиц: каждой из них соответствует своя отдельная роль в сценариях. Если мы хотим отслеживать, когда и почему произошли определенные события внутри системы и кто стал их причиной, то необходимо формализовать роли всех пользователей. Например, при рассмотрении жалобы нам возможно придется выяснить, кто вел переговоры с недовольным клиентом. Кроме того, нам понадобится эта классификация при разработке механизма ограничения доступа к различным частям системы для различных групп пользователей. В открытой системе централизованный контроль вполне эффективен и неизбежен: он уменьшает риск случайного или целенаправленного неправильного использования.
В результате анализа был выделен ряд ключевых абстракций, каждая из которых представляет собой определенный тип информации в системе:
-
CustomerRecord - информация о клиенте
-
ProductRecord - информация о товаре
-
SupplierRecord - информация о поставщике
-
Order - заказ от клиента
-
PurchaseOrder - заказ поставщику
-
Invoice - счет
-
PackingOrder - расходная накладная
-
StockingOrder - приходная накладная
-
ShippingLabel - документ на отгрузку
Классы CustomerRecord, ProductRecord и SupplierRecord связаны соответственно с абстракциями Customer, Product и Supplier. Мы, однако разделили эти два типа абстракций, так как они будут играть несколько разные роли.
Заметим, что существуют два вида счетов: те, которые посылаются компанией клиентам для оплаты заказанного товара, и те, которые компания получает от поставщиков товаров. Не отличаясь ничем по своей структуре, они, тем не менее, играют совершенно разные роли в системе.
По классам PackingOrder и StockingOrder потребуются некоторые дополнительные разъяснения. В соответствии с первыми двумя сценариями, после того, как сотрудник отдела продаж (OrderAgent) принимает заказ (order) от клиента (Customer), он должен дать указание кладовщику (StockPerson) на выдачу заказанного товара. В нашей системе соответствующая транзакция связана с объектом класса PackingOrder (расходная накладная). Этот класс ответственен за сбор всей информации, касающейся выписки расходной накладной по данному заказу. На операционном уровне это означает, что наша система формирует, а затем передает заказ на переносной компьютер одного из свободных в данный момент кладовщиков. Такая информация должна, как минимум, включать в себя идентификационный номер заказа, наименование и количество каждого из товаров. Нетрудно догадаться, как можно намного улучшить данный сценарий: наша система в состоянии передать кладовщику местоположение товаров, и, возможно, даже примерную последовательность вывоза их со склада, обеспечивающую максимальную эффективность этой операции [Конечно, в общем случае это известная задача о бродячем торговце, которая как известно, NP-полная. Однако, можно существенно ограничить задачу так, чтобы получались приемлемые решения. На самом деле, правила перевозки могут предписывать некое частичное упорядочение: сначала класть тяжелые грузы, потом легкие. Желательно также группировать грузы по типу: штаны с рубашками, молотки с гвоздями, колеса с шинами (мы предупредили, что речь идет об общецелевой системе учета!)]. В нашей системе достаточно информации, чтобы обеспечить помощь недавно принятому на работу кладовщику - например, дать ему возможность вывести на экран своего переносного компьютера изображение внешнего вида того или иного товара. Такая поддержка может пригодиться и опытному кладовщику на период смены ассортимента товаров.
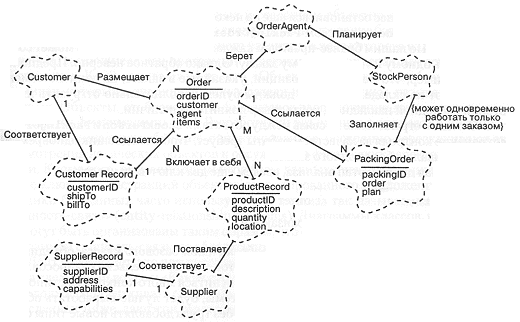 Рис. 10-4. Ключевые классы при приеме и выполнении заказа.
Рис. 10-4. Ключевые классы при приеме и выполнении заказа.
Рис. 10-4 содержит диаграмму классов, которая отражает наше понимание процесса взаимодействия некоторых из перечисленных абстракций в сценарии приема и выполнения заказа. Мы дополнили эту диаграмму некоторыми украшениями атрибутов, играющих важную роль в функционировании каждого из классов.
Основные мотивы введения именно такой структуры классов связаны с учетом перехода между экземплярами классов. Получив заказ, мы бы хотели, в частности, сформировать маркер, обозначающий клиента, сделавшего заказ; для этого необходимо перейти от экземпляра класса заказа (order) обратно к клиенту (customer). Получив расходную накладную, надо возвратиться к клиенту и к сотруднику отдела продаж для передачи информации об отгрузке; это означает, что нам потребуется перейти от расходной накладной к заказу, и затем от него - к клиенту и сотруднику отдела продаж. Что касается клиента, то желательно знать, какие товары он чаще всего заказывает в то или иное время года. Для выполнении такого запроса необходимо вернуться от клиента ко всем предыдущим его заказам.
Стоит подробнее остановиться еще на некоторых деталях диаграммы. Почему между классом Order и классом PackingOrder существует отношение 1:N (один ко многим)? По нашим бизнес-правилам каждая расходная накладная может соответствовать одному и только одному заказу. Однако обратное неверно. Предположим, например, что некоторые позиции, указанные в заказе, на данный момент отсутствуют на складе. Тогда мы должны будем дополнительно отгрузить их по второй расходной накладной, когда товар появится в наличии.
Отметим ограничение на связь между объектами StockPerson и PackingOrder: сохранение контроля за качеством работы требует, чтобы кладовщик одновременно обслуживал не более одного заказа.
Завершая данный этап анализа, введем еще два ключевых класса:
-
Report - отчет
-
Transaction - транзакция
Мы ввели абстракцию Report для обозначения базового класса, объединяющего все различные типы печатных документов и пользовательских запросов, При детальном анализе всех сценариев может выясниться много конкретных типов документов, но, ввиду открытости нашей системы, будет лучше выработать общий механизм генерации отчетов, позволяющий без труда добавлять новые типы отчетов. Действительно, выделив общие для всех отчетов свойства, мы сможем наделить их общим поведением и структурой, что позволит придать соответствующим элементам системы стандартизованный вид и облегчит для конечного пользователя работу с системой.
Наш список далеко не полон, но у нас накопилось достаточно информации для перехода к разработке архитектуры системы. Однако, до того, необходимо рассмотреть некоторые принципы, влияющие на организацию структур данных внутри программы.
Модели баз данных
Дэйт рассматривает базу данных как "вместилище хранимой информации. Она, как правило, одновременно является и интегрированной, и общедоступной. Под "интегрированностью" имеется в виду то, что базу данных можно представить как объединение нескольких отдельных файлов данных, избыточность информации в которых частично или полностью исключена... Под "общедоступностью" имеется в виду то, что информация, содержащаяся в базе, может одновременно использоваться сразу несколькими пользователями" [7]. При централизованном управлении базой данных можно "устранять несоответствия, устанавливать стандарты, накладывать ограничения на доступ к информации и поддерживать целостность базы данных" [8].
Разработка эффективной базы данных является трудной задачей, так как к ней предъявляется много взаимно противоречивых требований. Проектировщик должен учитывать не только функциональные требования к приложению, но также быстродействие и размер базы данных. Базы данных, неэффективные по быстродействию, оказываются, как правило, бесполезными. Системы, для реализации которых надо забить компьютерами все здание и нанять толпу администраторов для ее поддержки, неэффективны с точки зрения стоимости.
Между разработкой базы данных и созданием объектно-ориентированного приложения существует много параллелей. Проектирование баз данных часто рассматривается как процесс итеративного развития, в ходе которого надо принимать решения, касающиеся как программной логики, так и аппаратных аспектов [9]. В©рковски и Кул указывают на то, что "Объекты, описывающие базу данных в терминах, которыми оперируют пользователи и разработчики, называются логическими. Объекты, отображающие физическое расположение данных в системе, называются физическими" [10]. Разработчики баз данных в процессе проектирования, напоминающем объектно-ориентированное, постоянно перескакивают от рассмотрения логических объектов к обсуждению физических аспектов их реализации. Кроме того, описание элементов базы данных очень напоминает перечисление ключевых абстракций объектно-ориентированного приложения. Проектировщики баз данных часто используют для анализа так называемые диаграммы "сущность-связь" (entity-relationship diagrams). Диаграммы классов, как мы видели, могут быть организованы таким образом, что будут напрямую соответствовать диаграммам сущность-связь, но обладать при этом еще большей выразительностью.
Дэйт утверждает, что при проектировании любой базы данных нужно дать ответ на следующий вопрос: "Какие структуры данных и соответствующие им операторы должна поддерживать система?" [11]. Три различные модели баз данных, перечисленные ниже, дают три различных ответа на этот вопрос:
-
иерархическая;
-
сетевая;
-
реляционная.
Недавно появился четвертый тип, а именно объектно-ориентированные базы данных (ООСУБД). ООСУБД соединяют традиционную технологию проектирования баз данных с объектной моделью. Применение такого подхода оказалось достаточно полезным в таких областях, как компьютерное проектирование (САЕ) и разработка программ с помощью компьютеров (CASE), где нам приходится манипулировать значительными объемами данных с разнообразным семантическим содержанием. Объектно-ориентированные базы данных могут дать для некоторых приложений значительный выигрыш в быстродействии по сравнению с традиционными реляционными базами данных. В частности, в случае наличия большого количества связей между таблицами, объектно-ориентированные базы данных могут работать значительно быстрее, чем реляционные. Более того, ООСУБД гарантируют согласованную "бесшовную" интеграцию данных и бизнес-правил. Чтобы достичь той же семантики, в реляционных базах используют сложную систему триггеров, которые формируются с помощью языков программирования третьего и четвертого поколений - модель, которую никак нельзя назвать ясной и понятной.
Однако по ряду причин многие компании считают, что использование реляционной базы данных в контексте объектно-ориентированной архитектуры менее рискованно. Технология реляционных баз данных значительно более зрелая, она реализована на широком спектре различных платформ и зачастую предлагает более полный набор средств защиты, контроля версий и поддержания целостности. Кроме того, компания, уже вложившая определенный капитал в кадры и в инструменты, поддерживающие реляционную модель, просто не может позволить себе изменить за одну ночь всю технологию работы.
Реляционная модель весьма популярна. Принимая во внимание ее большую распространенность, широкий набор программных продуктов, ее поддерживающих, а также тот факт, что она удовлетворяет функциональным требованиям к системе складского учета, мы выбрали именно ее. Таким образом, мы остановились на гибридном решении: построение объектно-ориентированной оболочки над традиционной реляционной базой и использование преимуществ обоих подходов. Рассмотрим вкратце некоторые основные принципы проектирования реляционных баз данных. Зная их, мы лучше поймем, как создать объектно-ориентированную оболочку.
Основными элементами реляционной базы данных являются "таблицы, в которых столбцы представляют собой предметы и их атрибуты, а строки описывают отдельные экземпляры предметов... Модель также подразумевает наличие операторов для генерации новых таблиц на базе старых: именно таким способом пользователи могут манипулировать данными и получать информацию из базы" [12].
Рассмотрим для примера базу данных склада с радиоэлектронными товарами, на котором хранятся резисторы, конденсаторы и микросхемы. Каждый тип продукции в соответствии с предыдущей диаграммой классов обладает уникальным идентификационным номером и описательным именем. Например:
Products
| productId |
description |
| 0081735 |
Resistor, 10 ае 1/4 watt |
| 0081736 |
Resistor, 10 ае 1/4 watt |
| 3891043 |
Capacitor, 100 pF |
| 9074000 |
7400 1С quad NAND |
| 9074001 |
74LS00 1С quad HAND |
Мы видим таблицу с двумя столбцами, каждый из которых представляет определенный атрибут. В данном случае порядок, в котором расположены строки (столбцы), не важен; количество строк не ограничено, но каждая из них должна быть уникальной. Первый столбец, productID, является первичным ключом, то есть он может быть использован для однозначной идентификации детали.
Товары поступают от поставщиков; информация о каждом из них должна содержать уникальный идентификатор поставщика, имя компании, ее адрес, и, возможно, телефонный номер. Таким образом, можно составить следующую таблицу:
Suppliers
| SupplierID |
Company |
Address |
Telephone |
| 00056 |
Interstate Supply |
2222 Fannin, Amarillo, TX |
806-555-0036 |
| 03107 |
Interstate Supply |
3320 Scott, Santa Clara, CA |
408-555-3600 |
| 78829 |
Universal Products |
2171 Parfet Ct, Lakewood, CD |
303-555-2405 |
supplierID - первичный ключ в том смысле, что им можно однозначно идентифицировать поставщика. Отметим, что все строки в этой таблице уникальны, однако у двух из них имя поставщика одинаково.
Различные поставщики предлагают различные продукты по различным ценам, поэтому мы можем организовать также таблицу стоимости продуктов. Она содержит текущую цену для каждой комбинации товар/поставщик:
Prices
| productID |
SupplierID |
Price |
| 0081735 |
03107 |
$0.10 |
| 0081735 |
78829 |
$0.09 |
| 0156999 |
78829 |
$367.75 |
| 7775098 |
03107 |
$10.69 |
| 6889655 |
00056 |
$0.09 |
| 9074001 |
03107 |
$1.75 |
В этой таблице нет простого первичного ключа. Для однозначной идентификации строк мы должны использовать комбинацию ключей productID и supplierID. Ключ, образуемый из значений различных столбцов, называется составным. Заметьте, что мы не включили в эту таблицу названия деталей и поставщиков - это было бы излишним; данную информацию можно отыскать по значениям полей productID и supplierID в таблицах товаров и поставщиков. Поля productID и supplierID называются внешними ключами, так как они представляют первичные ключи других таблиц.
На рис. 10-5 представлена структура классов, соответствующая этим таблицам. Здесь, для обозначения записей, которые имеют смысл только в совокупности с записями из других таблиц, мы используем ассоциацию с атрибутом. Первичные ключи таблиц заключены в квадратные скобки.
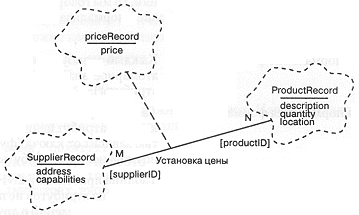 Рис. 10-5. Ассоциация с атрибутами.
Рис. 10-5. Ассоциация с атрибутами.
Далее, мы можем проверить состояние склада с помощью таблицы, содержащей количество всех имеющихся в наличии продуктов:
Inventory
| ProductId |
Quantity |
| 0081735 |
1000 |
| 0097890 |
2000 |
| 0156999 |
34 |
| 7775098 |
46 |
| 6889655 |
1 |
| 9074001 |
92 |
Эта таблица показывает, что объектно-ориентированное представление данных системы может отличаться от их представления в базе данных. В схеме, представленной на рис. 10-4, quantity является атрибутом класса ProductRecord, a здесь, в целях обеспечения быстродействия, мы решили разместить quantity в отдельной таблице. Дело в том, что, как правило, описание товара (description) модифицируется очень редко, в то время как количество (quantity) меняется постоянно по мере того, как со склада отгружаются товары и на склад прибывают новые грузы. Для оптимизации доступа к количеству товара разумнее выделить его в отдельную таблицу.
Данная деталь реализации системы, как следует из рис. 10-4, не будет видна клиентам нашего приложения. Класс ProductRecord создает иллюзию того, что quantity является его частью.
Самой очевидной и в то же время наиболее важной целью проектирования базы данных является построение такой схемы размещения данных, при которой каждый факт хранится в одном и только в одном месте. При этом не происходит дублирования информации, упрощается процесс внесения изменений в базу данных и поддержания ее целостности (согласованности и правильности данных). Достигнуть цели не всегда бывает легко (оказывается, что это и не всегда нужно). Тем не менее, в нашем случае данное свойство будет очень желательным.
Для достижения этой цели (важной, но не единственной [13]) была разработана специальная теория нормализации. Нормализация есть свойство таблицы; если таблица удовлетворяет определенным условиям, то мы говорим что она имеет нормальную форму. Существует несколько уровней нормализации, каждый из которых базируется на предыдущем [14]:
| ® Первая нормальная форма (1NF) |
Каждый атрибут представляет собой атомарное значение (неразложимые атрибуты). |
| ® Вторая нормальная форма (2NF) |
Таблица приведена в 1NF, и при этом каждый атрибут целиком и полностью зависит от ключа (функционально независимые атрибуты). |
| ® Третья нормальная форма (3NF) |
Таблица приведена в 2NF, и при этом ни один из атрибутов не предоставляет никаких сведений о другом атрибуте (взаимно независимые атрибуты). |
Таблица в третьей нормальной форме "содержит свойства ключа, весь ключ и ничего кроме ключа" [15].
Все рассмотренные таблицы находятся в 3NF. Существуют еще более высокие уровни нормализации, в основном связанные с многозначными фактами, но в данном случае они не имеют для нас большого значения.
Для того, чтобы связать воедино объектно-ориентированную схему и реляционную модель, иногда нам приходится сознательно нарушать нормализацию таблиц, внося в них определенную избыточность. При этом нам придется прилагать специальные усилия для поддержания синхронизации избыточных данных, однако взамен мы получаем возможность более быстрого доступа к данным, что для нас важнее.
SQL
При работе с объектно-ориентированной моделью, где данные и формы поведения соединены воедино, пользователю может понадобиться осуществить ряд транзакций с таблицами. Он, например, может захотеть добавить в базу нового поставщика, исключить из нее некоторые товары или изменить количество имеющегося в наличии товара. Может также появиться необходимость сделать различные выборки из базы данных, например, просмотреть список всех продуктов от определенного поставщика или получить список товаров, количество которых на складе недостаточно или избыточно с точки зрения заданного нами критерия. Может, наконец, понадобиться создать исчерпывающий отчет, в котором оценивается стоимость пополнения запасов до определенного уровня, используя наименее дорогих поставщиков. Подобные типы транзакций присутствуют почти в каждом приложении, использующем реляционную базу данных. Для взаимодействия с реляционными СУБД разработан стандартный язык - SQL (Structured Query Language, язык структурированных запросов). SQL может использоваться и в интерактивном режиме, и для программирования.
Самой важной конструкцией языка SQL является предложение SELECT следующего вида:
SELECT <attribute> FROM <relation> WHERE
<condition>
Для того чтобы, например, получить коды продуктов, чей запас на складе меньше 100 единиц, можно написать следующее:
SELECT PRODUCTID, QUANTITY FROM INVENTORY WHERE
QUANTITY < 100
Возможно создание и более сложных выборок. Например такой,
где вместо кода товара фигурирует его наименование:
SELECT NAME, QUANTITY
FROM INVENTORY, PRODUCTS
WHERE QUANTITY < 100 AND INVENTORY.PRODUCTID
= PRODUCTS.PRODUCTID
В этом предложении присутствует связь, позволяющая как бы объединять несколько отношений в одно. Данное предложение SELECT не создает новой таблицы, но оно возвращает набор строк. Одна выборка может содержать сколь угодно большое число строк, поэтому мы должны иметь средства для доступа к информации в каждой из них. Для этого в языке SQL введено понятие курсора, смысл которого схож с итерацией, о которой мы говорили в главе 3. Можно, например, определить курсор следующим образом:
DECLARE С CURSOR
FOR SELECT NAME, QUANTITY
FROM INVENTORY, PRODUCTS
WHERE QUANTITY < 100 AND INVENTORY.PRODUCTID
= PRODUCTS.PRODUCTID
Чтобы открыть эту выборку, мы пишем
OPEN C
Для прочтения записей выборки используется оператор FETCH:
FETCH C INTO NAME, AMOUNT
И, наконец, после того, как работа завершена, мы закрываем
курсор;
CLOSE C
Вместо использования курсора можно пойти другим путем: создать виртуальную таблицу, где содержатся результаты выборки. Такая виртуальная таблица называется представлением. С ним можно работать как с настоящей таблицей. Создадим, например, представление, содержащее наименование товара, имя поставщика и стоимость:
CREATE VIEW V (NAME, COMPANY, COST) AS
SELECT PRODUCTS.NAME, SUPPLIERS.COMPANY, PRICES.PRICE
FROM PRODUCTS, SUPPLIERS, PRICES
WHERE PRODUCTS.PRODUCTID = PRICES.PRODUCTID AND
SUPPLIERS.SUPPLIERID = PRICES.SUPPLIERID
Использование представлений предпочтительнее, так как оно позволяет создавать различные представления для различных клиентов системы. Поскольку представления могут существенно отличаться от низкоуровневых связей в базе данных, гарантируется некоторая степень независимости данных. Права доступа пользователей к информации можно определять на основе виртуальных, а не реальных таблиц, позволяя таким образом записывать безопасные транзакции. Представления несколько отличаются от таблиц, хотя бы тем, что связи в представлениях не могут быть обновлены напрямую.
В нашей системе SQL-запросы будут играть роль абстракций низкого уровня. Пользователи вряд ли будут разбираться в SQL, ведь этот язык не является частью предметной области. Мы будем использовать SQL при реализации программы. Составлять свои SQL-предложения смогут только достаточно искушенные в программировании разработчики инструментальных средств нашей системы. От простых смертных, работающих с системой каждый день, язык запросов будет скрыт.
Рассмотрим следующую задачу: получив заказ, мы хотим определить имя сделавшей его компании. С точки зрения программиста SQL, это нетрудная задача. Однако, в нашем случае, когда основное программирование выполняется на C++, мы предпочли бы использовать следующее выражение:
currentOrder.customer().name()
С точки зрения объектно-ориентированного подхода это выражение вызывает селектор customer, возвращающий ссылку на клиента, а затем - селектор name, возвращающий имя клиента. На самом деле данное выражение вычисляется следующим запросом:
SELECT NAME
FROM ORDERS, CUSTOMERS
WHERE ORDERS.CUSTOMERID = CURRENTORDER.CUSTOMERID
AND ORDERS.CUSTOMERID = CUSTOMERS.CUSTOMERID
Спрятав от клиента детали реализации данного вызова, мы скрыли от него все неприятные особенности работы с SQL.
Отображение объектно-ориентированного представления мира в реляционное концептуально ясно, но обычно требует довольно утомительной проработки деталей [Большая часть преимуществ объектно-ориентированных баз данных заключается как раз в том, что в них эти утомительные детали скрыты от разработчика. Отображение классов в таблицы достаточно легко алгоритмизуемо, поэтому существует альтернатива ООСУБД: инструментальные средства, которые автоматически преобразуют определения классов C++ в реляционную схему и SQL-код. Тогда, например, если приложение запрашивает атрибут данного объекта, сгенерированный код создает необходимые SQL-предложения для стандартной реляционной базы данных, получает требуемые данные и доставляет их клиенту в форме, согласованной с интерфейсом C++]. По замечанию Румбаха, "Соединение объектной модели с реляционной базой данных - в целом довольно простая задача, за исключением вопросов, связанных с обобщением" [16]. Румбах предлагает также некоторые правила, которые следует учитывать при отображении классов и ассоциаций (включая агрегацию) на таблицы:
-
Каждый класс отображается в одну или несколько таблиц.
-
Каждое отношение "многие ко многим" отображается в отдельную
таблицу.
-
Каждое отношение "один ко многим" отображается в отдельную таблицу или соотносится с внешним ключом [17].
Далее он предлагает три альтернативных варианта отображения иерархии наследования в таблицы:
-
Суперкласс и каждый его подкласс отображаются в таблицу.
-
Атрибуты суперкласса реплицируются в каждой таблице (и каждый подкласс отображается в отдельную таблицу).
-
Атрибуты всех подклассов переносятся на уровень суперкласса (таким образом мы имеем одну таблицу для всей иерархии наследования) [18].
Нет ничего удивительного в том, что существуют определенные ограничения по использованию SQL в низкоуровневой реализации [Недавно был предложен новый стандарт - SQL3, который содержит объектно-ориентированные расширения. Они существенно уменьшают семантические различия между объектно-ориентированным и реляционным взглядом на мир и устраняют многие другие ограничения SQL]. В частности, этот язык поддерживает ограниченный набор типов данных, а именно, символы, строки фиксированной длины, целые числа и вещественные числа с фиксированной и плавающей точкой. Отдельные реализации иногда умеют работать и с другими типами данных; однако представление информации в виде графических элементов или строк произвольной длины напрямую не поддерживается.
Анализ схем данных
Дэйт задается следующим вопросом: "Пусть дан набор данных, которые надо расположить в базе данных. Как определить подходящую логическую структуру для этих данных? Другими словами, как определить связи и атрибуты? Это и есть задача проектирования базы данных" [19]. Оказывается, что идентификация ключевых абстракций базы данных во многом напоминает процесс идентификации классов и объектов. По этой причине мы начнем разработку системы складского учета сразу с объектно-ориентированного анализа, в процессе которого будет формироваться структура базы данных, а не будем сперва браться за создание схемы базы данных, и затем выводить из нее объектную модель.
Начнем с уже перечисленного нами списка основных абстракций. Применив к нему правила Румбаха, мы получим следующие таблицы базы данных (сначала перечислим те из них, которые соответствуют ролям групп, принимающих участие в работе системы):
-
CustomerTable
-
SupplierTable
-
OrderAgentTable
-
AccountantTable
-
ShippingAgentTable
-
StockPersonTable
-
RecetvingAgentTable
-
FlannelTable
Затем следуют таблицы, отражающие классификацию продуктов
и их наличие на складе:
-
ProductTable
-
InventoryTable
И, наконец, мы вводим таблицы для документопотока:
-
OrderTable
-
PurchaseOrderTable
-
InvoiceTable
-
PackingOrderTable
-
StockOrderTable
-
ShippingLabelTable
Мы не создавали таблиц для классов Report и Transaction, - результаты анализа подсказывают, что объекты этих классов не нуждаются в хранении.
На следующем этапе анализа можно в деталях определить состав атрибутов всех перечисленных таблиц. Наверно, нет смысла обсуждать на страницах этой книги данные вопросы; мы уже останавливались на наиболее интересных свойствах этих абстракции (см. рис. 10-4), а оставшиеся атрибуты дают мало нового с точки зрения архитектуры системы.
10.2. Проектирование
Формулируя подходы к архитектуре системы складского учета, мы должны помнить о трех моментах организационного характера: разделение функций между клиентской и серверной частью, механизм управления транзакциями, стратегия реализации клиентской части приложения.
Архитектура клиент/сервер
Наиболее важным вопросом реализации архитектуры клиент/сервер является не столько вопрос о том, где будет проведена граница между этими двумя частями, сколько о том, как разумно произвести это разделение. Возвращаясь к первоосновам, ответ на этот вопрос нам известен: нужно сосредоточиться на поведении каждой абстракции, основывающемся на анализе вариантов использования каждой сущности, и только затем принять решение о размещении поведения. После того, как мы проделаем такую работу в отношении нескольких основных объектов, станут ясны общие механизмы, понимание которых поможет нам правильно разместить оставшиеся абстракции.
Для примера рассмотрим поведение классов Order и ProductRecord. Анализ первого из них дает нам следующий перечень необходимых операций:
-
construct
-
setCustomer
-
setOrderAgent
-
addItem
-
removeItem
-
orderID
-
customer
-
orderAgent
-
numberOfItems
-
itemAt
-
quantityOf
-
totalValue
Перечисленные сервисные операции можно сразу выразить на языке C++, предварительно дав два новых определения типов:
// типы идентификационных номеров
typedef unsigned int OrderID;
// тип, описывающий местную валюту
typedef float Money;
Теперь получаем следующее определение класса:
class Order {
public:
Order();
Order(OrderID);
Order(const Order&);
~Order();
Orders operator=(const Orders);
int operator==(const Orders) const;
int operator!=(const Orders) const;
void setCustomer(Customer&);
void setOrderAgent(OrderAgent&);
void addItem(Product&, unsigned int quantity
= 1);
void removeItem(unsigned int index, unsigned int
quantity = 1);
OrderID orderID() const;
Customer& customer() const;
OrderAgent& orderAgent() const;
unsigned int numberOfItem() const;
Product& itemAt (unsigned int) const;
unsigned int quantityOf(unsigned int) const;
Money totalValue() const;
protected:
...
};
Обратим внимание на наличие нескольких вариантов конструктора. Первый из них используется по умолчанию (Order()) для создания объекта с новым уникальным значением идентификатора OrderID. Копирующий конструктор также создает объект с уникальным идентификатором, но при этом копирует в него состояние объекта, использованного в качестве аргумента.
Последний конструктор принимает в качестве аргумента OrderID, то есть конструирует объект уже существующий в базе данных и извлекает из базы его параметры. Другими словами, в этом случае мы повторно материализуем объект, существующий в базе данных. Такая операция, безусловно, требует выполнения некоторых действий: при восстановлении объекта из базы данных соответствующий SQL-механизм должен либо сделать объект разделяемым, либо синхронизировать состояние двух объектов, созданных в разных приложениях. Детали, конечно, скрыты в реализации и недоступны клиенту, который использует объект, применяя обычный объектный интерфейс.
Реализация описанного подхода не вызывает особых затруднений. Если класс Order спроектирован так, что его состояние полностью определяется идентификатором OrderID, то реализация операций сводится к обычным операторам чтения и записи из базы данных. Копии объектов синхронизируются, поскольку соответствующая таблица в базе служит единым репозиторием состояния для всех представлений одного объекта.
Диаграмма объектов на рис. 10-6 иллюстрирует описанный SQL-механизм на примере сценария выставления счета. В сценарии реализованы следующие события:
-
aClient активизирует операцию setCustomer применительно к объекту класса Order; объект класса Customer передается в качестве параметра.
-
Объект класса Order вызывает селектор customerID c параметром заказчика, позволяющим получить из базы данных соответствующий первичный ключ.
-
Объект, соответствующий заказу, использует SQL-оператор UPDATE, чтобы установить идентификатор заказчика в базе данных заказов.
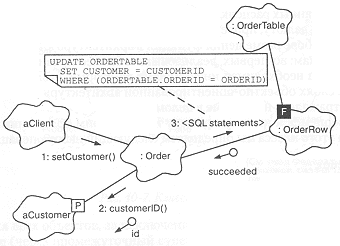 Рис. 10-6. Выставление счета.
Рис. 10-6. Выставление счета.
Описанный механизм предполагает, что мы можем положиться на существующий в базе данных механизм блокировки записей и взаимного исключения при доступе (представьте себе, что могло бы случиться при одновременном обновлении одной записи из двух приложений). Если этот механизм блокировки должен быть видимым для клиента, то можно воспользоваться тем же подходом, который использовался нами при создании библиотеки классов в главе 9. Ниже мы покажем, что механизм выполнения транзакции позволяет модифицировать за один прием несколько записей в базе, обеспечивая тем самым целостность базы данных.
После реализации описанного механизма вопрос о размещении бизнес-логики имеет скорее тактическое значение. В этом смысле ситуация не отличается от той. которую мы имели бы в не объектно-ориентированной архитектуре. Но в объектно-ориентированной архитектуре можно изменить эти решения, скрыв сам факт изменения от клиента. Таким образом, клиента не затрагивают изменения, которые мы делаем по ходу настройки системы.
Для примера рассмотрим два различных случая. Добавление в базу данных записей о наличии продуктов или удаление их, очевидно, должно согласовываться с бизнес-логикой, поэтому кажется естественным разместить бизнес-логику на сервере. Добавление сведении о новых продуктах в базу данных требует точного их определения и однозначной идентификации. Кроме того, эти данные необходимо сделать доступными для всех клиентов, чтобы обновить их кэшированные таблицы. Удаление продукта из базы также требует проверки на наличие заказов по этому продукту и предупреждения соответствующих клиентов [Для этих семантических отношений как раз и придумали триггеры: они описывают реакцию на некоторые существенные события в базе данных. Приняв объектно-ориентированный взгляд на мир. можно формализовать это соглашение об использовании триггеров, инкапсулируя их как часть семантики операций с объектами базы данных].
Напротив, расчет стоимости заказов является более локальной операцией и его лучше выполнять в клиентской части приложения. Выполняя подсчеты, мы запрашиваем в базе данных расцепки на все элементы заказа, складываем их, пересчитываем в нужную валюту, проверяем на допустимые условия кредитования и т.д.
Итак, при выборе размещения функции в архитектуре клиент/сервер мы следуем двум правилам: во-первых, реализовывать бизнес-правила и алгоритмы там где сосредоточена необходимая информация; во-вторых, размещать эти алгоритмы в нижних слоях объектно-ориентированной архитектуры, чтобы внесение изменении не отражалось на системе в целом.
Теперь вернемся к нашему примеру и рассмотрим более внимательно класс Product. Для этого класса мы определяем следующий набор операций:
-
construct
-
setDescription
-
setQuantity
-
setLocation
-
setSupplier
-
productID
-
description
-
quantity
-
location
-
supplier
Эти операции являются общими для всех видов товаров. Однако, анализ частных случаев показывает, что есть продукты, для которых эти характеристики недостаточны. С учетом того, что проектируемая система является открытой, а виды товаров могут быть самыми различными, приведем несколько примеров специфических товаров и их свойств:
-
Скоропортящиеся продукты, требующие определенного режима хранения.
-
Едкие и токсичные химические вещества, также требующие специального обращения.
-
Комплектные товары, которые поставляются в определенных сочетаниях (например, радиопередатчики и приемники) и поэтому взаимозависимы.
-
Высокотехнологичные компоненты, поставки которых ограничиваются законодательством стран-экспортеров.
Перечисленные примеры наводят на мысль о необходимости создания некоторой иерархии классов товаров. Однако, перечисленные свойства настолько различны, что не образуют никакой иерархии. В данной ситуации более целесообразно воспользоваться примесями, что иллюстрирует и рис. 10-7. Обратим внимание на использование в этой диаграмме украшений ограничения, уточняющих семантику каждой абстракции.
Каков смысл наследования для абстракций, отражающих сущности реляционной базы данных? Очень большой: построение иерархии наследования сопровождается вычленением общих признаков поведения и отображением их в структуре суперклассов. Эти суперклассы будут ответственны за реализацию общего поведения для всех объектов, за исключением тех подклассов, которые уточняют это поведение (через промежуточный суперкласс) или расширяют его (через суперкласс-примесь). Такой подход не только упрощает построение системы, но и повышает устойчивость к вносимым изменениям за счет сокращения избыточности и локализации общих структур и поведения.
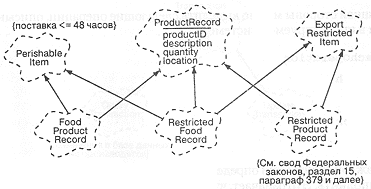 Рис. 10-7. Классы товаров.
Рис. 10-7. Классы товаров.
Механизм транзакций
Архитектура клиент/сервер построена на взаимодействии клиентской и серверной частей приложения, для реализации которого необходим определенный механизм. Берсон указал, что "существует три базовых вида взаимодействия между процессами в архитектуре клиент/сервер" [20]:
-
конвейеры (pipes)
-
удаленный вызов процедур (RPC)
-
взаимодействие клиент/сервер через SQL.
В нашем примере мы воспользовались только третьим способом. Но, в общем случае, могут использоваться все указанные виды взаимодействия в соответствии с требованиями производительности или в результате выбора программных средств конкретного поставщика. В любом случае наш выбор должен быть скрыт, чтобы не оказывать влияния на абстракции высокого уровня.
Мы ранее уже упомянули о классе транзакции, но не остановились подробно на его семантике. Берсон определяет транзакцию как "единицу обмена и обработки информации между локальной и удаленной программами, которая отражает логически законченную операцию или результат" [21]. Это и есть определение нужной нам абстракции: объект-транзакция является агентом, ответственным за выполнение некоторого удаленного действия, а, следовательно, отчетливо отделяет само действие от механизма его реализации.
Действительно, транзакция является основным высокоуровневым видом взаимодействия сервера и клиента, а также между клиентами. На основе этого понятия можно выполнять конкретный анализ вариантов использования. Принципиально все основные функции в системе складского учета могут рассматриваться как транзакции. Например, размещение нового заказа, подтверждение поступления товаров и изменения информации о поставщиках являются системными транзакциями.
С внешней стороны можно выделить следующие операции, описывающие суть поведения в проектируемой системе:
-
attachOperation
-
dispatch
-
commit
-
rollback
-
status
Для каждой транзакции определяется полный перечень операций, которые она должна выполнить. Это означает, что для класса Transaction необходимо определить функции-члены, такие как attachOperation, которые предоставляют другим объектам возможность объединить набор SQL-операторов для исполнения в качестве единой транзакции.
Интересно отметить, что такое объектно-ориентированное видение транзакций полностью согласуется с принципами, принятыми в практике работы с базами данных. Дэйт определил, что "транзакция представляет собой последовательность операторов SQL (возможно, не только SQL), которые должны быть неразделимы в смысле произведения отката и управления параллельным доступом" [Date, C.[E 1987], c.32].
Концепция атомарности наиболее существенна в семантике транзакций. Если в некоторой транзакции операция выполняется над несколькими строками таблицы, то либо все действия должны быть выполнены, либо содержимое таблицы должно быть оставлено без изменении. Следовательно, когда мы посылаем транзакцию (dispatch), мы имеем в виду выполнение группы операций как единого целого.
При благополучном завершении транзакции мы должны зафиксировать ее результаты (commit). Невыполнение транзакции может произойти в силу ряда причин, в том числе из-за отказов сети или блокировки информации другими клиентами. В таких ситуациях выполняется откат в исходное состояние (rollback). Селектор status возвращает значение параметра, определяющего успешность транзакции.
Выполнение транзакции несколько усложняется при работе с распределенными базами данных. Как реализовать протокол завершения транзакций при работе с локальной базой достаточно понятно, а что необходимо сделать при работе с данными, размещенными на нескольких серверах? Для этого используется так называемый двухфазный протокол завершения транзакций [23]. В этом случае агент, то есть объект класса Transaction, разделяет транзакцию на несколько фрагментов и раздает их для выполнения различным серверам. Это называется фазой подготовки. Когда все серверы сообщили о том, что готовы к завершению, центральный агент транзакции передает им всем команду commit. Это называется фазой завершения. Только при правильном завершении всех разделенных компонент транзакции основная транзакция считается завершенной. Если хотя бы на одном сервере выполнение операций будет неполным, мы откатим всю транзакцию. Это возможно потому, что каждый экземпляр Transaction знает, как откатить свою транзакцию.
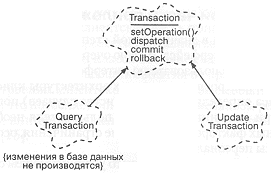 Рис. 10-8. Транзакции.
Рис. 10-8. Транзакции.
Изложенное выше представление о классе транзакций показано на рис. 10-8. Мы видим здесь иерархию транзакций. Класс Transaction является базовым для всех транзакций и содержит в себе все ключевые аспекты поведения. Производные специализированные классы вносят в общее поведение свои особенности. Мы различаем, например, классы UpdateTransaction и QueryTransaccion, потому что их семантика очень различна: первый из них модифицирует данные на сервере баз данных, а второй - нет. Различая эти и другие типы транзакций, мы собираем в базовом классе наиболее общие характеристики, и пополняем при этом наш словарь.
В процессе дальнейшего проектирования мы, возможно, обнаружим и другие разновидности транзакций, которые будут представлены собственными подклассами. Например, если мы убедимся, что операции добавления и удаления данных из конкретной базы имеют общую семантику, то введем операции AddTransaction и DeleteTransaction, чтобы отразить эту общность поведения.
Во всяком случае, существование базового класса Transaction позволяет выполнять нам любое атомарное действие. Например, на C++ он мог бы выглядеть так:
public:
Transaction();
virtual ~Transaction();
virtual void setOperation(const UnboundedCollection<SQLStatement>&);
virtual int dispatch();
virtual void commit();
virtual void rollback();
virtual int status() const;
protected:
...
};
Обратим внимание, что для построения этого класса мы использовали базовые классы, определенные нами в главе 9. В данном случае мы построили транзакцию в форме индексированной коллекции операторов. Для манипулирования этой коллекцией использован параметризованный класс UnboundedCollection.
Принятое архитектурное решение позволяет сложному пользовательскому приложению выполнять наборы SQL-операторов. Все детали реализации механизма управления транзакциями оказываются скрытыми для простых клиентов, которым достаточно выполнять некоторые общие типы транзакции.
Создание клиентской части приложения
Создание клиентской части в значительной степени сводится к построению графического прикладного интерфейса. В свою очередь, построение удобного интуитивного и дружественного пользователю интерфейса - скорее искусство, чем наука. В приложениях, построенных в рамках архитектуры клиент/сервер, именно качество интерфейса определяет (в большинстве случаев) популярность тех или иных программ. При создании интерфейса пользователя необходимо учитывать множество различных факторов: технические ограничения, особенности психологии, традиции, вкусы персонала.
При создании нашей системы складского учета мы можем столкнуться с двумя препятствиями. Во-первых, нужно выяснить, каким должен быть "правильный" интерфейс пользователя. Во-вторых, желательно определить, какие общепринятые подходы мы можем использовать при создании интерфейса.
Ответ на первый вопрос можно получить достаточно просто, но для этого нужно прототипировать, прототипировать и прототипировать. Нужно как можно раньше получить действующую модель системы, чтобы показать ее пользователям и получить от них квалифицированные замечания. Объектно-ориентированный подход существенно поможет нам в этом смысле, поскольку он основан на итерационном развитии проекта. На самых ранних стадиях проекта мы уже сможем показать пользователям прототип системы.
Второй вопрос находится в сфере стратегии проекта, но для его успешного разрешения у нас имеется множество хороших примеров. Существуют коммерческие продукты, например, Х Window System от MIT, Open Look, Windows от Microsoft, MacApp от Apple, NextStep от Next, Presentation Manager от IBM. Все эти продукты существенно различаются: некоторые основываются на сети, а некоторые опираются на концепцию ядра, некоторые позволяют действовать на уровне пикселей, а другие считают примитивами более сложные геометрические фигуры. В любом случае все они позволяют существенно упростить создание графического интерфейса пользователя. Ни один из перечисленных продуктов не родился за одну ночь. Все они постепенно развивались из самых простых систем, прошли путь проб и ошибок. В результате эти системы вобрали в себя набор абстракций, достаточный для построения пользовательского интерфейса. Поскольку нет однозначного ответа на вопрос о лучшем интерфейсе, то существуют несколько вариантов оконной модели.
В главе 9 мы уже упоминали о том, что при работе с большими библиотеками классов (каковыми являются и библиотеки графического интерфейса) важно понять механизмы их построения. Для нашей задачи основным механизмом является реакция GUI-приложений на события. Берсон указывал, что для клиентской части приложения существенны события, связанные со следующими объектами [24]:
-
мышь
-
клавиатура
-
меню
-
обновление окна
-
изменения размера окна
-
активизация/деактивация
-
начало/завершение.
Мы добавим к этому перечню сетевые события [Например, механизмы DDE (Dynamic Data Exchange, динамический обмен данными) и OLE (Object Linking and Embedding, связь и внедрение объектов) от Microsoft представляют собой основанные на сообщениях протоколы, обеспечивающие обмен информацией между приложениями Windows]. Для нашей архитектуры они очень существенны, поскольку клиентская часть приложения связана с другими компонентами и приложениями через сеть. Описанная семантика хорошо согласуется с нашим подходом к построению класса Transaction, который может рассматриваться как посредник, пересылающий события от приложения к приложению. С точки зрения построения клиентской части, сетевые события являются разновидностью событий, что позволяет описать единый механизм реакции на события.
Берсон обратил внимание на наличие нескольких альтернативных моделей обработки событий [25]:
| ® Цикл обработки событий |
В цикле просматривается очередь событии и для каждого
события вызывается соответствующая процедура обработки. |
| ® Обратный вызов |
Приложение регистрирует функцию обратного вызова для каждого элемента GUI; обратный вызов происходит, когда элемент зарегистрирует событие. |
| ® Гибридная модель |
Сочетание циклического опроса и функций обратного вызова. |
Изрядно упрощая, можно утверждать, что в интерфейсе MacApp используется цикл, в Motif - функции обратного вызова, a Microsoft Windows является примером гибридной модели.
Кроме первичного механизма, нам необходимо реализовать еще множество GUI-механизмов: рисование, прокрутка, работа с мытью, меню, сохранение и восстановление, печать, редактирование, обработка ошибок, распределение памяти. Безусловно, подробное рассмотрение всех этих вопросов находится вне рамок нашего анализа, поскольку каждая конкретная GUI-среда имеет свои собственные реализации этих механизмов.
Мы предлагаем разработчику клиентской части приложения выбрать подходящую GUI-среду разработки, изучить ее основные механизмы и правильно их применить.
10.3. Эволюция
Управление релизами
Теперь, полностью определив архитектурный каркас системы складского учета, мы можем приступить к последовательному развитию. Выберем сначала наиболее важные транзакции в нашей системе (ее вертикальный срез) и выпустим продукт, который по крайней мере симулирует выполнение транзакций.
Для примера остановимся на трех простых транзакциях: занесение в базу нового клиента, добавление товара и принятие заказа. При реализации этих транзакций мы в той или иной степени затронем практически все архитектурные интерфейсы. Если мы сможем успешно преодолеть этот ключевой этап, то дальше будем выпускать релизы в следующем порядке:
-
Модификация или удаление данных о клиентах; модификация или удаление данных о продуктах: модификация заказа; запросы о клиентах, заказах и продуктах.
-
Интеграция всех похожих транзакции, связанных с поставщиками: создание заказа и выписка счета.
-
Интеграция всех оставшихся транзакций, связанных со складом: составление отчетов и выписка расходных накладных.
-
Интеграция всех оставшихся транзакций, связанных с бухгалтерией: поступление оплаты.
-
Интеграция всех оставшихся транзакции, связанных с отгрузкой.
-
Интеграция всех оставшихся транзакций, связанных с планированием.
При общем сроке проектирования системы в 12-18 месяцев необходимо каждые 3 месяца выпускать рабочий релиз программы. К окончанию срока все необходимые для работы системы транзакции будут охвачены.
В главе 6 уже упоминалось, что ключевым моментом при такой стратегам является выявление риска, поэтому для каждого релиза мы находим самое опасное место и активно прорабатываем его. Для приложений клиент/сервер это связано, в первую очередь, с возможно более ранним тестированием вместимости и масштабируемости (чтобы как можно раньше найти узкие места системы и сделать с ними что-нибудь). При этом в каждый релиз следует включать транзакции из разных функциональных элементов системы - тогда будет меньше шансов столкнуться с неожиданностями.
Генераторы приложений
При создании приложений типа системы складского учета необходимо произвести множество экранных форм и отчетов. Для больших систем эта работа не столько сложна, сколько велика по объему и однообразна. По этой причине сегодня весьма популярны генераторы приложений на основе языков четвертого поколения (4GL). Использование этих языков не противоречит идеям объектно-ориентированного проектирования. Напротив, 4GL-языки позволяют при правильном применении существенно упростить написание кода.
Языки четвертого поколения используются для генерации экранных форм и отчетов. На основании спецификаций они создают исполняемый код форм и отчетов. Мы интегрируем этот код в нашу систему, "оборачивая" его вручную тонким объектно-ориентированным слоем. Таким образом код, сгенерированный 4GL, становится частью структуры классов, которую остальные части приложения могут использовать, не обращая внимание на то, как она была создана.
Такой подход позволяет нам воспользоваться преимуществами 4GL, сохраняя иллюзию полностью объектно-ориентированной архитектуры. Кроме того, языки четвертого поколения сами подвергаются сильному влиянию технологии объект-но-ориентированного программирования и включают в себя прикладные интер-фейсы (API) для объектно-ориентированных языков типа C++.
Такую же стратегию можно использовать и при реализации диалога пользователя с системой. Написание программ для модального и немодального диалога скучно, поскольку мы должны охватить массу мелких деталей. Лучше не писать такой код вручную [Можно получать удовольствие и от самого процесса написания объектно-ориентированных программ, но гораздо важнее сосредоточиться на требованиях поставленной задачи. Это означает, что нужно избегать написания нового кода, где только возможно. Генераторы приложений и GUI-конструкторы очень способствуют этому. Среды разработки, которые мы описывали в главе 9, предоставляют еще один важный пример такого рода], а использовать GUI-конструкторы, позволяющие "рисовать окна диалога. После получения готового кода мы заворачиваем его в объектную оболочку, включаем в наше приложение и получаем систему с четким разделением обязанностей.
10.4. Сопровождение
Системы клиент/сервер редко бывают окончательно завершенными. Не то чтоб мы никогда не могли сказать про систему, что она уже стабильна. Просто систем должна развиваться вместе с бизнесом, чтобы оставаться полезной.
Можно указать некоторые направления модернизации, которые вероятны для системы складского учета:
-
Предоставить возможность клиентам работать с системой по каналам связи.
-
Автоматически генерировать индивидуальные каталоги товаров для потребительских групп или даже отдельных клиентов.
-
Полностью автоматизировать все функции, устранив кладовщиков и большую часть работающих на приеме и отгрузке.
Анализ показывает, что все перечисленные модификации связаны скорее с со циалъным и политическим риском, чем с техническим. Гибкая объектно-ориентированная архитектура системы позволяет заказчику использовать все степени свободы, чтобы адаптироваться к постоянно меняющемуся рынку.
Дополнительная литература
Об архитектуре клиент/сервер написано больше, чем большинство смертных способно прочесть за всю жизнь. Две наиболее полезные ссылки - это Девайр (Dewire) [H 1992] и Берсон (Berson) [H 1992], которые предложили исчерпывающие и хорошо читаемые обзоры по всему спектру проблем технологии клиент/сервер. Блум (Bloom) [H 1993] дал короткое, но интересное перечисление базовых понятий и проблем архитектуры клиент/сервер.
Децентрализация - это не то же самое, что вычисления в архитектуре клиент/сервер, хотя она и предусматривает вычисления в архитектуре клиент/сервер в корпоративных информационно-управляющих системах. Все мотивировки за и против децентрализации можно найти в работе Гвенджерича (Guengerich) [H 1992].
Исчерпывающее обсуждение технологии реляционных баз данных можно найти у Дэйта (Date) [Е 1981,1983,1986]. Вдобавок к этому, Дэйт (Date) [E 1987] предложил описание стандарта SQL. Разные подходы к анализу данных могут быть найдены у Вериярда (Veryard) [В 1984], Хавришкевича (Hawryszkiewycz) [Е 1984) и Росса (Ross) [F 1987).
Объектно-ориентированные базы данных представляют собой сплав обычной технологии баз данных и объектной модели. Отчеты о работе в этой области можно найти у Кэттла (Cattle) (Е 1991], Атвуда (Atwood) [Е 1991], Дэвиса и др. (Davis et al.) [H 1983], Кима и Лочовского (Kim and Lochovsky) [H 1989], Здоника и Майера (Zdonik and Maier) [E 1990].
В библиографии приведены несколько ссылок на различные оконные системы и объектно-ориентированные интерфейсы пользователя. Подробности о Microsoft Windows API можно найти в Windows [G 1992], а относительно Apple МасАрр - в Масарр [G 1992].
|

